Can we generate high-dimensional semantic representations discretely, just like language models generate text?
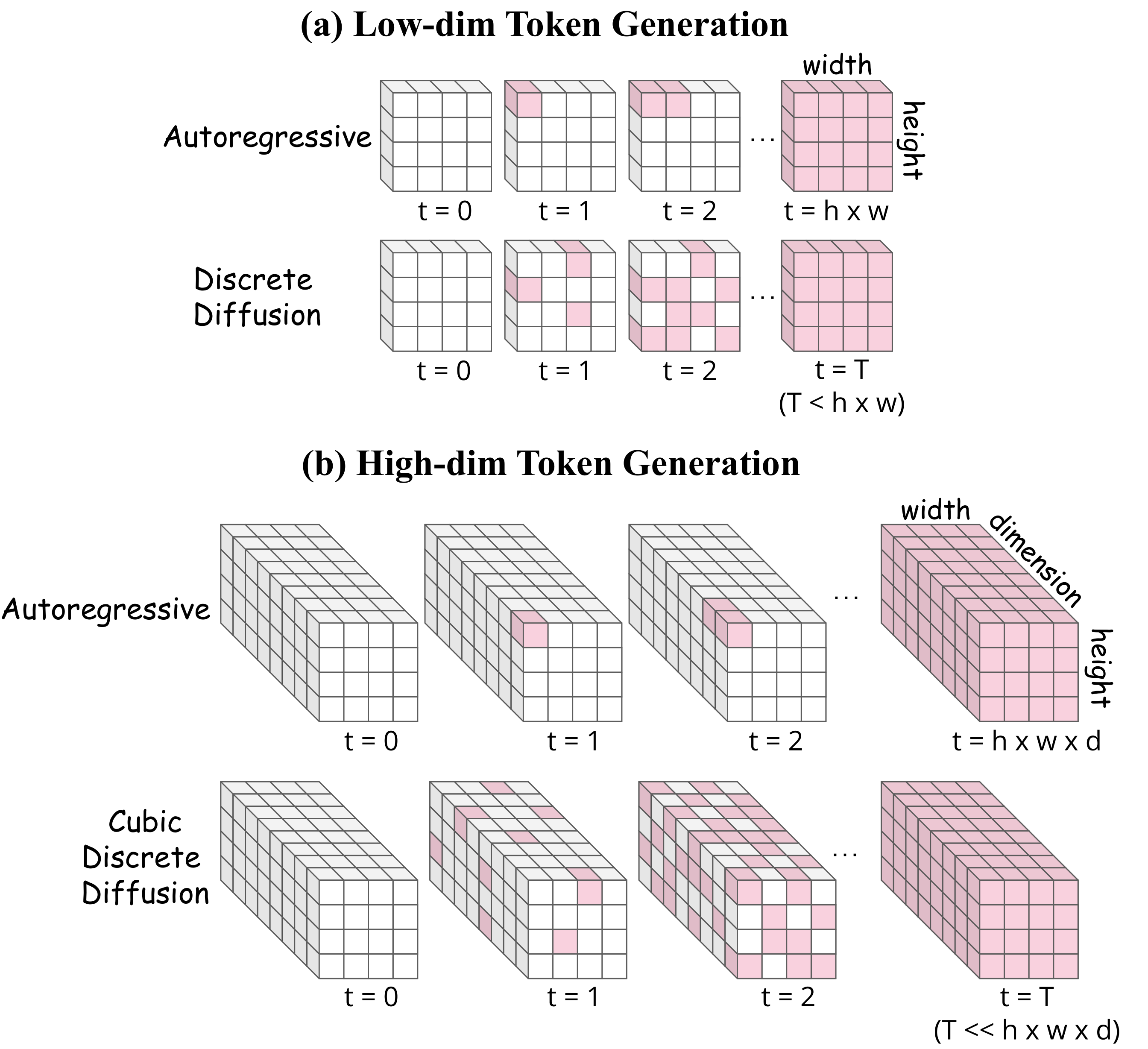
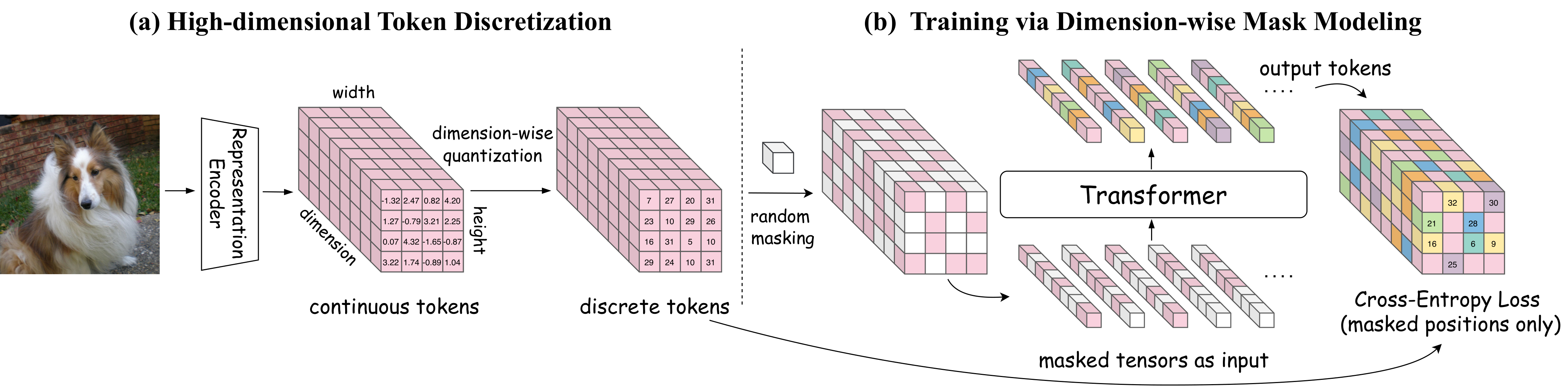
Generating high-dimensional semantic representations has long been a pursuit for visual generation, yet discrete methods—the paradigm shared with language models—remain stuck with low-dimensional tokens. CubiD breaks this barrier with fine-grained cubic masking across the h×w×d tensor, directly modeling dependencies across both spatial and dimensional axes in 768-dim representation space, while the discretized tokens preserve their original understanding capabilities.

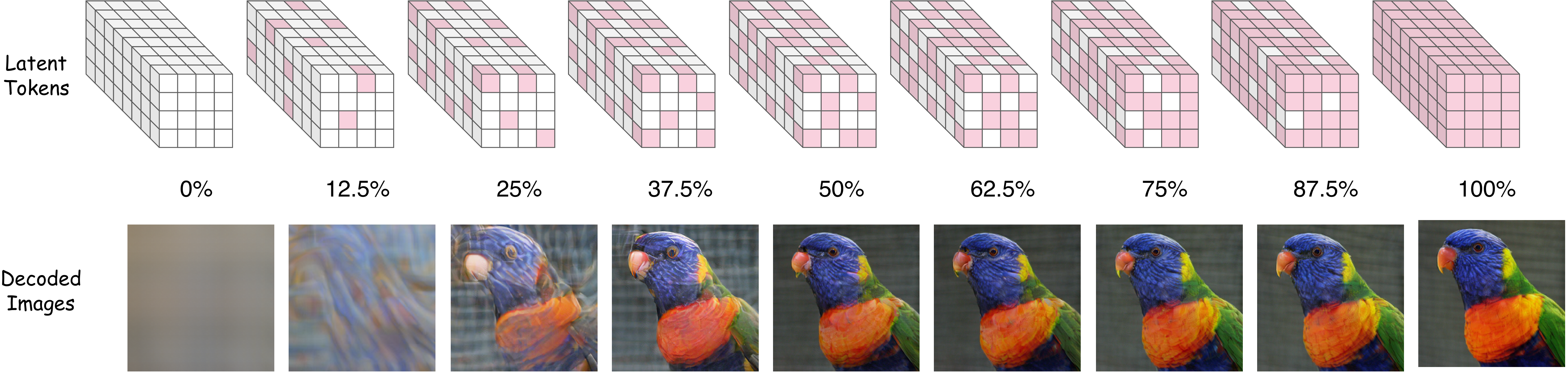
Generated samples from CubiD. Class-conditional generation on ImageNet 256×256 using 768-dimensional discrete representation tokens from DINOv2-B.